
واژه «رگرسیون» (Regression) به معنای «بازگشت» بوده و نشان دهندۀ آن است که مقدار یک متغیر به متغیر دیگری بر می گردد.
این واژه را اولین بار Francis Galton (فرانسیس گالتُن) در سال 1877 میلادی به کار برد. وی در تحقیقی متوجه شد که قد پسران خانواده با قد والدین آنها مرتبط است.
بعدها آماردانان سعی کردند به توسعۀ روابطی بپردازند که بتوان با آن میزان متغیری را با توجه به میزان دو یا چند متغیر دیگر پیدا کرد و بدین ترتیب از واژۀ Multiple Regression (رگرسیون چندگانه) استفاده کردند.
رگرسیون خطی ساده :
مدل یک رگرسیون خطی ب فرم زیر است، شکل 1-6:

هدف رگرسیون خطی ساده است که با آن برآورد پارمترهای B0 و B1، مدل خطی ساده را به داده ها برازش دهد. روشی که جهت Fit (فیت یا برازش) کردن بهترین خط به طریق ریاضی به کار می رود در قرن نوزدهم میلادی توسط ریاضیدان فرانسوی به نام Adrien Legendre (آدرین لژاندر) مطرح شد که به روش Least Square (حداقل مربعات) و یا به اختصار LS مرسوم است.
د راین روش معادلۀ خط برازنده طوری تشکیل می شود که مجموع مربعات توان های دوم انحراف های عمودی از خط فیت شده حداقل، و برآورد ضرایب با روش حداقل مربعات صورت می گیرد.
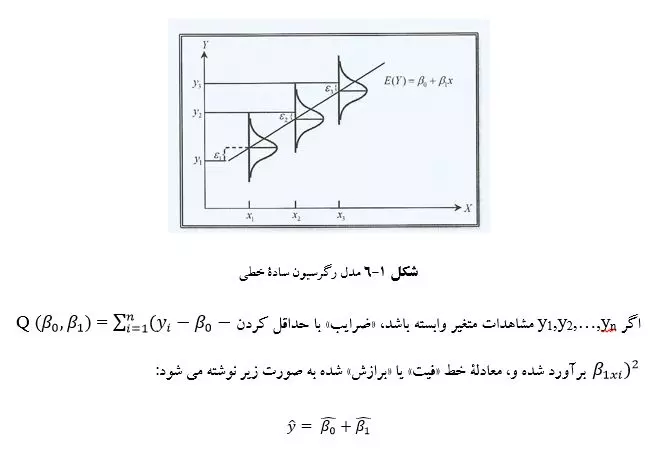
که بهy ̂ ها «مقادیر فیت شده»، (Fitted Values) یا «مقادیر پیش بینی شده » (Predicted values) گفته می شود.
به مقادیر ε ̂=y-y ̂ مانده ها (Residual) می گوییم که بعد از فیت کردن مدل باید با مطالعه این مقادیر، بازبینی هایی روی مدل داشته باشیم. در بررسی مدل فرض می شود که:
مانده ها دارای توزیع نرمال هستند. واریانس ثابت است.
متغیرها مستقل از یکدیگر هستند در محیط نرم افزاری SPSS از دستور Analyze > Regression > Linear…برای تحلیل «رگرسیون خطی ساده» (simple linear Regression) استففاده می شود.
کار با این ویژگی در مثال های زیر توضیح داده می شود.
مثال 1:
داده های جدول 1-6 میزان تجربه (بر حسب هفته) و تعداد کالاهای تولید شده معیوب برای 12 کارگر انتخابی، طی یک روز، را نشان می دهد.
معادلۀ خط رگرسیون را برآورد کنید.

پاسخ:
1- داده ها را به SPSS وارد کنید، شکل 2-6.
2- دستور Analyze > Regression > Linear… را اجرا کنید.
3- در پنجرۀ linear regression (رگرسیون خطی) متغیر Defect Goods (Defect) را تحت عنوان متغیر وابسته به ناحیۀ مستطیلی Dependent منتقل کنید. اکنون ، متغیر Experience Rate (Experience) (میزان تجربه) را به عنوان «متغیر مستقل» به ناحیۀ مستطیلی Independent(s) منتقل کنید، شکل 3-6.
4- روی دکمۀ ok کلیک کنید، خروجی 1-6


همانطور که در خروجی فوق می بینید، جداول مختلفی به شما نشان داده می شود که ما فعلا جدول Coefficients (ضرایب) را بررسی می کنیم:
پارامتر های برآورد شده در جدول Coefficients نشان داده شده و عبارتند از:

علاوه بر این، «انحراف معیار بر آوردها» (std. Error)، «ضرایب استاندارد شده» (standardized coefficients)، آماره های t و P –Value های مربوطه در این خروجی نشان داده شده است.
از این آماره ها برای آزمون فرض های آماری زیر استفاده می شود:


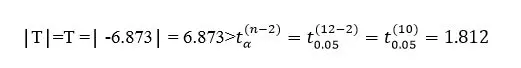
بنابراین، فرض H0 رد می شود و به عبارت دیگر، عرض از مبداء معادلۀ رگرسیونی صفر نیست.
روش دیگر جهت این آزمون، استفاده از P-Value است: P-Value = 0.0 < α= 0.05 پس نتیجه کلی این است که فرض H0 در سطح معنی داری پنج درصد رد می شود.
یعنی معادلۀ رگرسیونی دارای slope (شیب) رگرسیونی است.
نکات :
- تاثیر جداگانه هر یک از متغیر های کمکی در مدل رگرسیونی را می توانید درجدولCoefficients (ضرایب ) ببینید.
- چنانچه روی داده هایتان از یک مدل رگرسیونی Hierarchicail (سلسله مراتبی) استفاده کرده اید ، مقادیر مدل نهایی را بررسی کنید.
- مقادیر Standardized Beta (بتای استاندارد شده) اهمیت هر کدام از «پیشگو» ها در مدل را نشان می دهد. هر چه این مقدار بیشتر باشد ، مبین مهم بودن آن است.
